
Ein wissenschaftlicher Durchbruch ermöglicht es, Gehirnaktivität direkt in verständliche Textbeschreibungen umzuwandeln. Eine in der Fachzeitschrift Science Advances veröffentlichte Studie stellt eine neue Technik vor, die mittels funktioneller Magnetresonanztomographie (fMRT) nicht nur visuelle Eindrücke, sondern auch erinnerte Erlebnisse einer Person in detaillierten Sätzen erfassen kann. Diese Entwicklung könnte die Kommunikation für Menschen ohne Sprachvermögen grundlegend verändern.
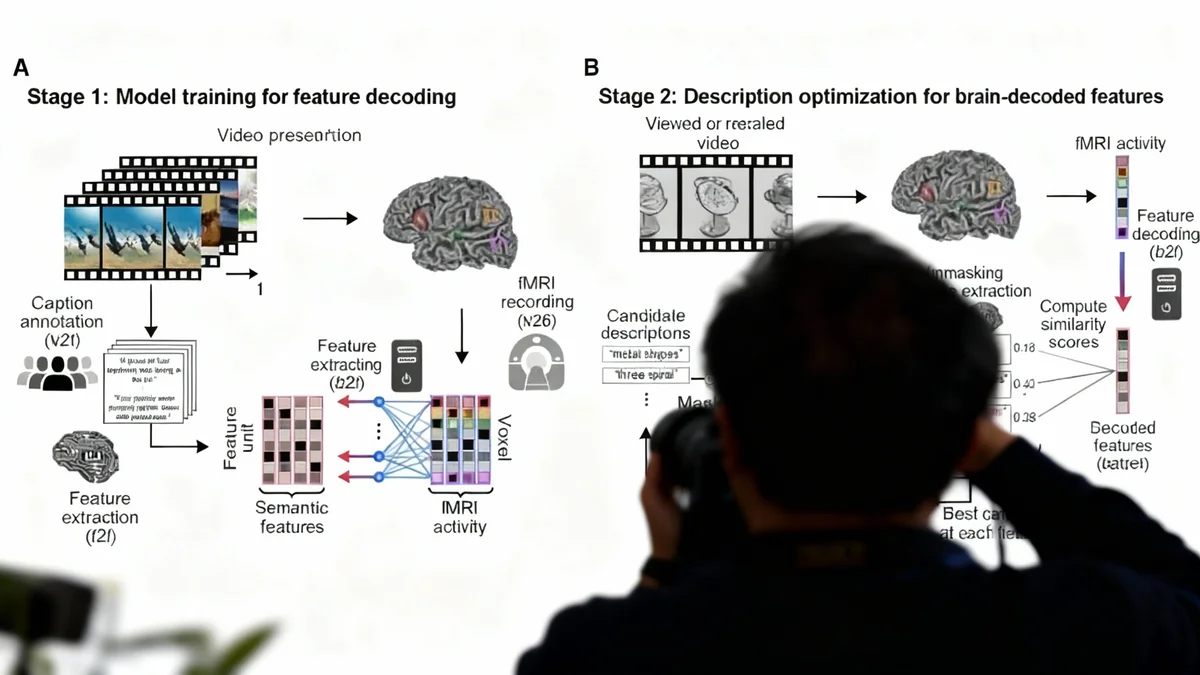
Die als „Mind-Captioning“ bezeichnete Methode nutzt künstliche Intelligenz, um semantische Merkmale aus den Gehirnscans zu dekodieren und sie mit den Strukturen eines Sprachmodells abzugleichen. Im Gegensatz zu früheren Ansätzen, die sich oft auf die Erkennung einzelner Wörter beschränkten, kann dieses System komplexe Zusammenhänge und dynamische Ereignisse beschreiben. Dies eröffnet neue Wege in der neurowissenschaftlichen Forschung und wirft gleichzeitig wichtige ethische Fragen zur Privatsphäre von Gedanken auf.
Wichtige Erkenntnisse
- Forscher haben eine KI-gestützte Methode entwickelt, um fMRT-Gehirnscans in detaillierte Textbeschreibungen zu übersetzen.
- Die Technik kann sowohl aktuell gesehene visuelle Inhalte als auch erinnerte Erlebnisse dekodieren.
- In Tests erreichte das System eine Genauigkeit von rund 50 % bei der Beschreibung von Videos, die Probanden sahen.
- Die Methode hat das Potenzial, die Kommunikation für Menschen mit Sprachverlust, beispielsweise nach einem Schlaganfall, zu revolutionieren.
- Die Entwicklung wirft wichtige ethische Fragen zum Schutz der mentalen Privatsphäre auf.
Wie Gedanken zu Worten werden
Die Technologie des Gedankenlesens ist keine neue Idee, doch bisherige Methoden waren stark eingeschränkt. Oft konnten sie nur einzelne Wörter identifizieren, die mit einem bestimmten Objekt oder einer Handlung verbunden waren. Die neue „Mind-Captioning“-Technik geht einen entscheidenden Schritt weiter. Sie verlässt sich nicht auf vordefinierte Wortdatenbanken, sondern nutzt einen dynamischen Prozess, um Sprache zu generieren.
Das Herzstück des Systems ist ein iterativer Optimierungsprozess. Dabei erzeugt ein sogenanntes maskiertes Sprachmodell (Masked Language Model, MLM) Textfragmente. Diese werden kontinuierlich mit den aus der Gehirnaktivität dekodierten semantischen Merkmalen verglichen und angepasst. Dieser Prozess wiederholt sich so lange, bis der generierte Text bestmöglich mit den im Gehirn gemessenen Signalen übereinstimmt.
„Anfangs waren die Beschreibungen fragmentiert und ohne klaren Sinn“, erklären die Autoren der Studie. „Durch die iterative Optimierung entwickelten diese Beschreibungen jedoch eine zusammenhängende Struktur und erfassten die Schlüsselaspekte der angesehenen Videos.“
Der Versuchsaufbau im Detail
Für die Studie wurden sechs Teilnehmer gebeten, sich insgesamt 2.196 kurze Videoclips anzusehen, während ihre Gehirnaktivität mit einem fMRT-Scanner aufgezeichnet wurde. Die Videos zeigten eine Vielzahl von Szenen, Objekten und Handlungen. Die Teilnehmer waren japanische Muttersprachler.
Die von der KI erzeugten Textbeschreibungen wurden anschließend mit von Menschen erstellten Bildunterschriften verglichen. Das Ergebnis war eine Trefferquote von etwa 50 Prozent. Obwohl diese Zahl auf den ersten Blick nicht perfekt erscheint, stellt sie laut den Forschern eine deutliche Verbesserung gegenüber bestehenden Technologien dar.
Technologie im Kern
Das System kombiniert mehrere KI-Modelle:
- fMRT: Erfasst die Gehirnaktivität durch Messung von Blutsauerstoffänderungen.
- DeBERTa-large: Ein Sprachmodell, das semantische Merkmale aus Texten extrahiert.
- RoBERTa-large: Ein maskiertes Sprachmodell, das den eigentlichen Text iterativ generiert.
Mehr als nur Bilder: Das Lesen von Erinnerungen
Eine der beeindruckendsten Fähigkeiten der neuen Methode ist ihre Anwendung auf Erinnerungen. In einem zweiten Teil des Experiments wurden dieselben sechs Teilnehmer gebeten, sich an die zuvor gesehenen Videos zu erinnern, während sie erneut im fMRT-Scanner lagen. Das Ziel war es herauszufinden, ob die Technologie auch innere, nicht-visuelle Gedankenprozesse dekodieren kann.
Die Ergebnisse waren vielversprechend. Das System konnte Beschreibungen generieren, die den Inhalt der erinnerten Videos widerspiegelten. Die Genauigkeit variierte zwar von Person zu Person, erreichte bei einigen Teilnehmern aber fast 40 Prozent bei der korrekten Zuordnung der Erinnerung aus einer Auswahl von 100 möglichen Videos.
Was ist fMRT?
Die funktionelle Magnetresonanztomographie (fMRT) ist ein bildgebendes Verfahren, das aktive Bereiche des Gehirns sichtbar macht. Es misst winzige Veränderungen im Blutfluss. Wenn ein Gehirnareal aktiv ist, benötigt es mehr Sauerstoff, der über das Blut zugeführt wird. Diese Veränderung des Sauerstoffgehalts wird vom fMRT-Gerät erfasst und in ein dreidimensionales Bild umgewandelt. So können Forscher sehen, welche Teile des Gehirns bei bestimmten Aufgaben wie Sehen, Sprechen oder Erinnern beteiligt sind.
Diese Fähigkeit, Gedächtnisinhalte zu lesen, ist von großer Bedeutung. Sie zeigt, dass die Technologie nicht nur auf die Verarbeitung externer Reize beschränkt ist, sondern auch auf die Interpretation abstrakter mentaler Zustände zugreifen kann. Dies ist ein entscheidender Unterschied zu vielen anderen Gehirn-Computer-Schnittstellen (BCIs).
Eine neue Hoffnung für die Kommunikation
Die potenziellen Anwendungsbereiche dieser Technologie sind enorm, insbesondere im medizinischen Bereich. Für Menschen, die ihre Fähigkeit zu sprechen verloren haben, etwa durch einen Schlaganfall, eine Amyotrophe Lateralsklerose (ALS) oder schwere Verletzungen, könnte „Mind-Captioning“ eine Tür zur Außenwelt öffnen.
Bestehende Kommunikationshilfen sind oft langsam und mühsam. Diese neue Methode verspricht eine direktere und nuanciertere Form der Kommunikation. Da sie in der Lage ist, komplexe Beziehungen und Bedeutungen zu erfassen, könnten Betroffene nicht nur einfache Wünsche, sondern auch komplexe Gedanken und Gefühle mitteilen.
„Zusammengenommen schafft unser Ansatz ein Gleichgewicht zwischen Interpretierbarkeit, Generalisierbarkeit und Leistung – er etabliert einen transparenten Rahmen für die Dekodierung nonverbaler Gedanken in Sprache.“
Bevor die Technologie jedoch im klinischen Alltag ankommt, ist weitere Forschung und Optimierung erforderlich. Die Genauigkeit muss weiter verbessert und die Methode an eine größere Vielfalt von Personen angepasst werden.
Die ethische Dimension des Gedankenlesens
So vielversprechend die Technologie auch ist, sie wirft unweigerlich ernste ethische Fragen auf. Die Möglichkeit, die Gedanken einer Person ohne deren aktive Mitarbeit zu lesen, birgt Risiken für die Privatsphäre und könnte missbraucht werden.
Die Forscher selbst betonen die Wichtigkeit der ethischen Auseinandersetzung. Die Einwilligung der betroffenen Person bleibt eine zentrale Voraussetzung für den Einsatz solcher Techniken. Es muss sichergestellt werden, dass die Technologie nur zum Wohle des Einzelnen und niemals gegen seinen Willen eingesetzt wird.
Wichtige Fragen, die geklärt werden müssen, sind:
- Wer hat Zugriff auf die dekodierten Gedanken?
- Wie können diese sensiblen Daten vor unbefugtem Zugriff geschützt werden?
- Welche rechtlichen Rahmenbedingungen sind notwendig, um die „mentale Privatsphäre“ zu schützen?
Bevor solche Technologien eine breite Anwendung finden, ist eine gesellschaftliche Debatte über diese Themen unerlässlich. Dennoch bietet die Studie einen faszinierenden Einblick in die Funktionsweise des menschlichen Gehirns und einen potenziellen Wendepunkt für die unterstützte Kommunikation.



